随着互联网上的信息量每分钟都在增加,从中检索有意义的数据有时就像大海捞针一样。基于内容的图像检索(CBIR)系统能够根据用户从广泛数据库中的输入检索所需的图像。
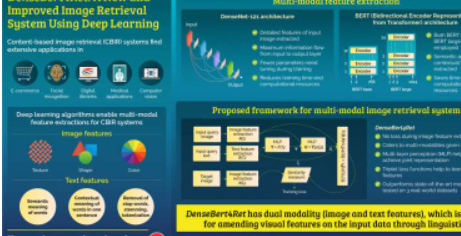
这些系统用于电子商务、人脸识别、医疗应用和计算机视觉。CBIR系统有两种工作方式——基于文本和基于图像。提升CBIR的方法之一是使用深度学习(DL)算法。DL算法支持使用多模态特征提取,这意味着图像和文本特征都可用于检索所需的图像。尽管科学家们已经尝试开发多模态特征提取,但它仍然是一个悬而未决的问题。
为此,光州科技学院的研究人员开发了DenseBert4Ret,这是一个使用DL算法的图像检索系统。这项研究由MoonguJeon教授和博士领导。学生ZafranKhan,发表在InformationSciences上。
“在我们的日常生活中,我们经常在互联网上搜索衣服、研究论文、新闻文章等。当这些查询出现在我们的脑海中时,它们可以是图像和文本的形式描述。此外,有时我们可能希望通过文本描述来修改我们的视觉感知。因此,检索系统也应该接受文本和图像的查询,”Jeon教授解释了团队研究背后的动机。
所提出的模型将图像和文本作为输入查询。为了从输入中提取图像特征,该团队使用了一种称为DenseNet-121的深度神经网络模型。这种架构允许从输入层到输出层的最大信息流,并且在训练期间需要调整很少的参数。
DenseNet-121与来自转换器(BERT)架构的双向编码器表示相结合,用于从文本输入中提取语义和上下文特征。这两种架构的结合减少了训练时间和计算要求,并形成了所提出的模型DenseBert4Ret。
然后,该团队使用三个真实世界数据集Fashion200k、MIT-states和FashionIQ来训练并比较提议的系统与最先进系统的性能。他们发现DenseBert4Ret在图像特征提取过程中没有表现出任何损失,并且优于最先进的模型。所提出的模型成功地满足了作为输入的多模态,多层感知器和三重损失函数有助于学习联合特征。
“我们的模型可以在任何有在线库存和需要检索图像的地方使用。此外,用户可以更改查询图像并从库存中检索修改后的图像,”Jeon教授总结道。